这是一篇介绍如何通过Python实现模拟登陆学校教务系统并爬取成绩相关信息(学期,课程名,总成绩,课程性质,学分)然后绘制成绩分布折线图最后导入MySQL数据库中的文章。
为了利用充分利用selenium的功能和成功爬取数据,需要有前置的html、css、简单爬虫的相关知识。
说明:我学校的成绩查询页面是通过加载js框架进而动态实时加载显示表格及数据的,如果仅仅是用一般的爬虫方法直接爬取页面信息,是不能成功的,因为那样是直接获取网页源码,其中并没有成绩数据。当然,采用某些爬虫方法肯定也能实现爬取js动态网页,但是我为了简单起见,直接用了selenium模拟登陆系统然后爬取信息。
Python构造代理ip池提高访问量
这是一篇介绍如何用Python构造代理ip池+采用BeautifulSoup方法提高网页浏览量的文章。
一般情况下,网页统计访问量的方法是:若一段时间内用同一ip访问某网页,则该网页访问量只增加1。于是我们可以采用不同的代理ip每隔一段时间对服务器进行一次网页访问请求,以实现增加访问量的目的。
具体代码如下:
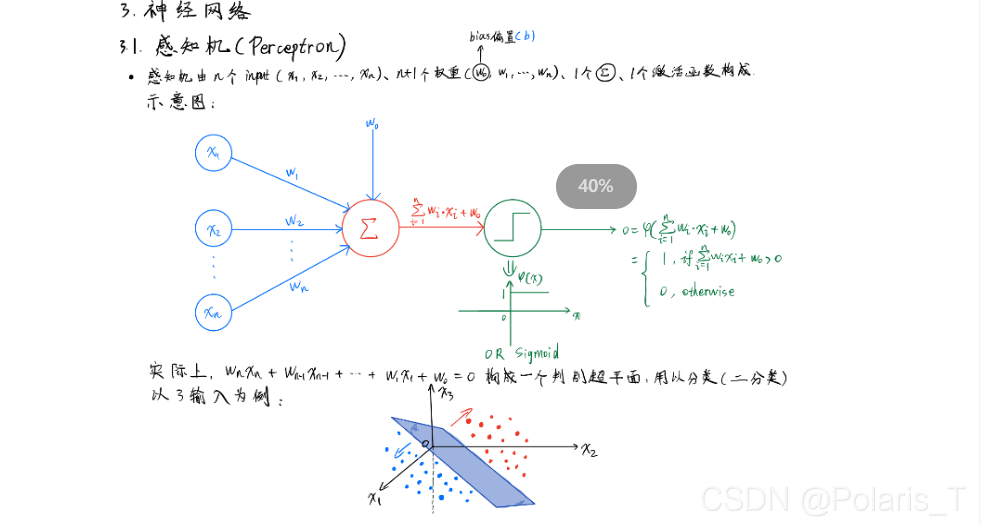
B站清华数据挖掘笔记(二)——感知机&手推BP神经网络权重更新公式
B站清华数据挖掘笔记(一)——朴素贝叶斯&决策树

B站清华数据挖掘笔记(三)——3类SVM支持向量机决策超平面的推导

B站清华数据挖掘笔记(五)——Apriori算法
