这是一篇介绍用Python进行基础的数据分析的文章,总结了其他博主文章的要点,主要分为6个部分:
1.生成或导入数据表
2.检查数据表
3.清洗数据表
4.数据预处理
5.数据汇总 | 数据统计 | 数据导出
6.自动化处理
1.生成或导入数据表
在使用 python 进行数据导入前,我们需要先导入 pandas 和 numpy 库。
1 | import numpy as np |
导入数据表(从csv/xlsx文件导入):
1 | df = pd.DataFrame(pd.read_csv('xxx.csv',header=1)) |
生成数据表
1 | # 列属性名columns以list形式给出,np.nan是NaN空值 |
打印刚才生成的数据表
1 | # 打印数据表 |
结果:
2.检查数据表
输出表维度及基本信息
1 | # 数据维度(6, 6) |
结果:显示表中数据的基本信息如数据类型,空值个数,占用空间大小等
输出数据表的全部列名称
1 | # 输出数据表的全部列名称 |
结果:
检查数据表的空值和唯一值
1 | # 检查数据表是否存在空值 |
结果:
查看数据表全部数值(以二维列表的形式返回)
1 | # 查看数据表数值,Python中的Values函数用来查看数据表中的数值,以二维列表的形式返回 |
结果:
查看数据表部分行的数据
1 | # 查看前4行数据 |
结果:
3.清洗数据表
清理存在空值的行
1 | # 删除数据表中含有空值的行,返回一个不含空值的数据框 |
结果:
空值的均值填充
1 | # 使用salary列的均值去填充salary列空值 |
结果: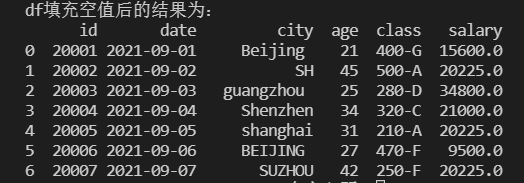
删除某一列中所有字符中的空格以及单词的大小写替换
1 | # 清除city列中所有字符中的空格 |
结果:
某一列数据的类型转换
1 | # 使用price列的均值去填充price列空值 |
结果: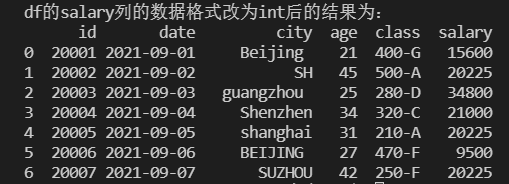
删除重复值所在行
1 | # 删除重复值 |
结果:
替换数据值
1 | # 数据替换 |
结果:
更改列属性名称
1 | # 更改列名称 |
结果:
4.数据预处理
数据表的合并
1 | #创建 df1 数据表 |
结果:
整张表按照某一列数据升序/降序排列
1 | # 数据表按某两列排序(一个主序列,一个辅助序列,当主序列出现相等情况时,按辅助序列值升序排列) |
结果: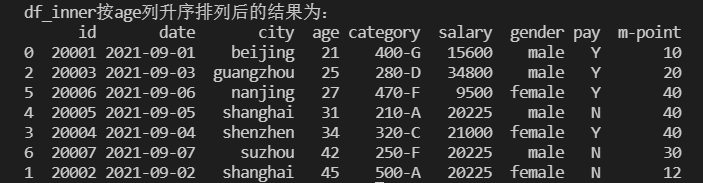
新建一列对某一列中符合条件的项进行标记
1 | # 对符合条件的项进行标记 |
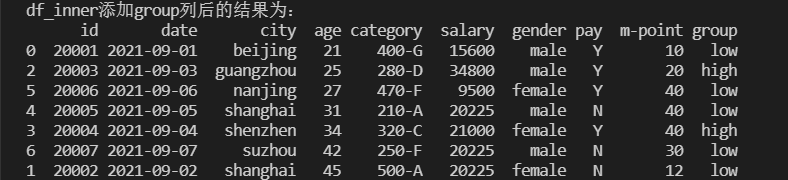
新建一列对某一列中符合多个条件的数据进行标记
1 | # 对符合多个条件的数据进行分组标记 |
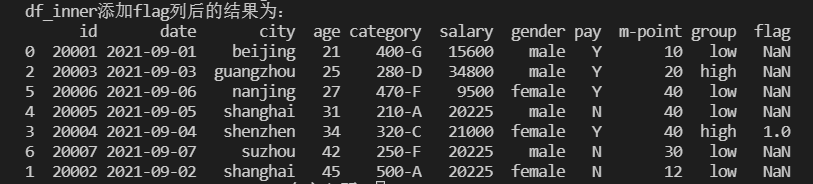
此时我们恢复数据表,按index升序排列
1 | # 恢复一下按index升序排列 |

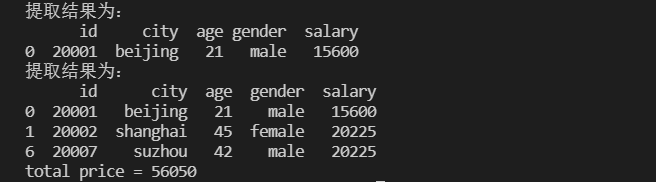
按行或位置提取数据(loc iloc)
1 | # 按数据表的--索引标签--提取数据(loc) |

按条件筛选(与,或,非)
1 | # 按条件筛选(与,或,非) |
5.数据汇总 | 数据统计 | 数据导出
数据表描述性的宏观统计,输出每一列的计数、均值、标准差等
1 | # 数据表描述性统计 |

输出标准差、协方差、相关系数、数据表各列之间的相关性分析
1 | # 标准差 |

输出至xlsx/csv
1 | #输出到excel格式 |
6.自动化处理(将一些重复性的机械操作封装)
例如把显示数据表基本信息的操作写入函数
1 | #创建自定义函数 |
结果: